Async generators (and their close friend for await) are a really cool feature of modern JavaScript that you can use when a loop requires asynchronous iteration. What the heck is that? Well let’s look at a regular for...of loop:
1 2 3 4 5 6 7 8
const array = [1, 2, 3]; for (const el of array) { console.log(el); }
// 1 // 2 // 3
Nothing weird here, we’re looping over an array and printing each element. An array is a synchronous data structure, so we can loop over it very simply. But what about asynchronous data, like say the fetch API to get data from a HTTP endpoint. A simple implementation of looping over that data is not much more complex:
1 2 3 4 5 6 7 8 9
const res = await fetch("https://whatever.com/api");
if (res.ok) { const data = await res.json();
for (const el of data) { console.log(el); } }
We’re still using for...of and being synchronous in our loop so let’s add one more factor: we’re using an API that uses pagination of some sort, which is pretty much every API ever made since it’s expensive to load giant datasets. A simple pagination-based iteration might look something like this:
do { const res = await fetch( `https://whatever.com/api?pageSize=${pageSize}&page=${page}` );
if (!res.ok) { thrownewError("Badly written error message"); }
const data = await res.json();
for (const el of data) { console.log(el); }
page++; } while (data.length === pageSize);
This is sort of async iteration but it suffers from a major shortcoming: you have to comingle the iteration code and the data fetching in the same loop as each page is ephemeral - or else select all the pages and allocate a monster array before you can deal with the data. Neither of those are great options, so let’s try an async generator function instead. An async generator is a function that returns an async iterable that you can loop over. Like other iterable and enumerable types (such as IEnumerable in C#), async iterables in JS are essentially an object with a next function to get the next thing in the iterable. This has several interesting side effects:
You cannot have random access to an iterable (it is forward-only)
Because it is forward only, memory need not be allocated for the entire iterable at the same time so it’s easily possible to have an iterable that has a nearly unlimited of iterations without running out of memory.
If you stop iterating, the rest of the elements in the iterable are never evaluated. For our pagination example, this means that if we stop reading at page 2, but page 3 exists, we’ll never fetch page 3 from the server.
For my own sanity I’m going to drop into TypeScript here to illustrate the types that we’re passing around :)
// This paginateAsync function implements generic pagination functionality over an arbitrary API, // using a passed in fetchPage function to tell it how to fetch a new page of data. // the * means the function is a generator (which returns an iterator) // and the async means it's an async generator, not a sync generator // (for C# readers, this is really similar to a method returning IEnumerable and using `yield return`) asyncfunction* paginateAsync<TResult>( fetchPage: (offset: number, limit: number) => Promise<TResult[]>, pageSize: number ): AsyncIterableIterator<TResult> { let offset = 0; let pageData: TResult[] = [];
do { // fetch one page of data pageData = await fetchPage(offset, pageSize);
// yield each item in the page (lets the async iterator move through one page of data) for (const item of pageData) { yield item; }
// increase the offset by the page count so the next iteration fetches fresh data offset += pageSize; } while (pageData.length === pageSize); }
// to use this function, we call it (note the lack of `await`; we're starting the iterator but requests don't occur until we loop over it) // then using the resulting iterator we can iterate over it using the `for await` loop: const iterator = paginateAsync( (offset, limit) => fetch(`https://whatever.com/api?limit=${limit}&offset=${offset}`), 100 );
forawait (const item of iterator) { // every time 100 iterations are done here, // a new API call will be sent for the next page. // this is transparent to your iteration. console.log(item);
// unlike returning a huge array from a single await, // this for await construct only ever has 100 items in memory at a time, // so you can tune your batch sizes.
// you can also abort the iteration before it's complete // for example if I break the loop after 199 items no request // for page 3 will ever be made. // if(index === 199) break; }
So now you can call a paginated API and treat the result as if it were a non-paginated loop. Pretty neat, right? Even better, you can use this in all modern browsers. (IE ain’t modern, folks…)
Again for my C# readers: this is pretty similar conceptually to C#’s IAsyncEnumerable construct and can be used in similar circumstances.
Netlify is an incredibly easy to use and powerful host for static sites. While this blog is not hosted there, I did deploy it to Netlify, no joke in less than 5 minutes. With automatic deployment of updates on commit. Check em out.
Anyhow today I had a monorepo that has more than one site that I wanted to deploy to Netlify. The repo looked something like this:
1 2 3 4
MyRepo └───sites ├───charlie.com └───nick.org
Netlify supports this but it’s not super well documented how to accomplish it without a little sleuthing.
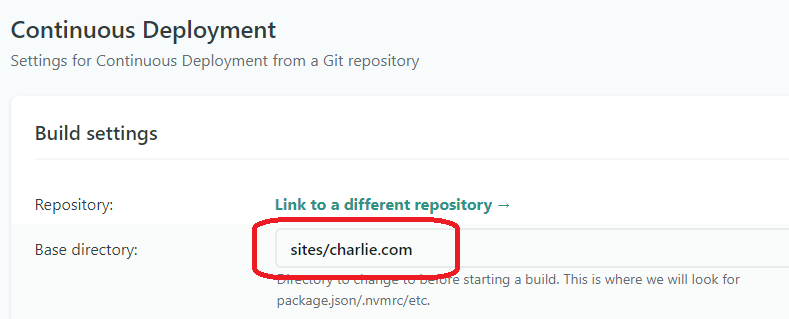
Monorepo support works by setting the Base directory of each site’s configuration to point at the relative path to your site root:
As it says on the tin, this essentially sets the path to cd to before starting the build commands. (Find it here: https://app.netlify.com/sites/<your-site-name-here>/settings/deploys)
But there’s one cool thing the description forgets to mention: You can also configure Netlify sites using a netlify.toml file, making your configuration versioned in Git. This gets really useful to control the whole build stack from one place: configuring the build commands, redirects, setting up lambda functions. Netlify usually expects netlify.toml in the root of the repository. However, the Base directory setting also changes where the netlify.toml is expected to live. If we do this:
In part 1 of this series, we investigated containerizing the JSS headless mode host. But there are some issues with that basic implementation:
We still have to pre-compile the JSS app to extract the server bundle, before building the container, and this compile step is not necessarily consistent with the production container environment since it depends on the host environment (different Node versions, OSes, etc are possible)
The standard Node container is pretty large (900MB), and though there are reasonable reasons for this, something smaller would be nice for production
Because the API key and Sitecore hostname are baked into the server bundle at build time, it would be necessary to maintain a container image for each environment
So, let’s fix this by using a build container to create a standardized build environment where we can make our server bundle. Basically,
Build Containers 101
When a Dockerfile executes, the state of each intermediate step is stored so that it need not be repeated every time the image rebuilds. But more importantly, you can also create intermediate build containers that live only long enough to perform a build step, then get thrown away except for some artifacts you want to persist on to some future part of the container build. In the case of our JSS image, the idea is something like this:
Create a full Node container
Copy the JSS app into it and run jss build
Create a lightweight Node container
Deploy the artifacts from the full Node container and the JSS headless app into it
The build container that we use to build the JSS app in is thrown away after the build occurs, leaving only the lightweight production container with its artifacts. In this case, thanks to switching from node:lts to node:lts-alpine as the base container, the built container size shrunk from 921MB to 93MB.
Note that because the base image is stored as a diff, the image size reduction affects the initial download time of the image on a new host, but once the node:lts image is cached it really only changes the amount of static disk space consumed.
Adding a build container step involves adding a few lines to the top of the Dockerfile from part 1:
# Create the build container (note aliasing it as 'build' so we can get artifacts later)
FROM node:lts as build
# Install the JSS CLI
RUN npm install -g @sitecore-jss/sitecore-jss-cli
# Set a working directory in the container, and copy our app's source files there
WORKDIR /build
COPY jss-angular /build
# Install the app's dependencies
RUN npm install
# Run the build
RUN npm run build
# Now, we need to switch contexts into the final container
# lts-alpine is a lightweight Node container, only 90MB
# When we switch contexts, the build container is supplanted
# as the context container
FROM node:lts-alpine
# ...
# When we copy the app's source into the final container
# we need to use --from=[tag] to get the files from our build container
# instead of the local disk
COPY --from=build /build/dist /jss/dist/${SITECORE_APP_NAME}
Tokenizing the Server Bundle
To solve the issue of the Sitecore API URL and API Key being baked into the server and browser bundles by webpack during jss build, we need to use tokenization. These values really do need to be baked into the file at some point, because the browser that executes them does not understand environment variables on your server or how to replace them - but, we should not need to re-run webpack every time a container starts up either.
We can work around this by baking specific, well-known tokens into the bundle files and then expanding those tokens when the container starts from environment variable values. The approach works something like this:
When the build container builds the JSS app, we force it to use specific well-known token values for the API host and API key, such as %sitecoreApiHost%
We move all the build output from the build container from *.js files to *.base files. This means the container itself does not contain any JS in its /dist. This is necessary so the container can generate the final files each time it starts up. (Since the same image can start many times with different environment variables present, it has to ‘rebake’ the JS each time)
Doing this is a bit harder than just doing the build container. First, during the container build in the Dockerfile:
# Before the build container runs the `build` command,
# we need to set specific API key and host values to bake
# into the build artifacts to replace later.
RUN jss setup --layoutServiceHost %layoutServiceHost% --apiKey 309ec3e9-b911-4a0b-aa8d-425045b6dcbd --nonInteractive
RUN npm run build
# After the build container runs the `build` command,
# we need to move all the .js files it emitted to .base files
RUN find dist/ -name '*.js' | xargs -I % mv % %.base
With the updated Dockerfile in place, the container we build will now have .base files ready to specialize into the running configuration when the container starts up. But without any changes to the image itself, it would fail because we can’t run an app using .base files! So we need to add a little script to the node-headless-ssr-proxy to perform this specialization when it starts up inside a container. The specialization process:
Copy all .base files to .js file of the same name (make a runtime copy to use in the browser)
Search & replace the well-known tokens in the .js files with the current runtime environment variables
Start the JSS headless proxy, which will now use the generated .js files and run normally
I used bootstrap.sh for the script name, but any name is fine.
This script is a rather hard to read one-liner so let’s piece it out to understand it:
find dist/ -name '*.base' | while read filename - Finds *.base files anywhere under dist, and reads each found filename into $filename in a loop body
do export jsname=$(echo $filename | sed -e 's|.base||') - Sets $jsname to the name of the found file, with the extension changed from .base to .js
cp $filename $jsname - copies the .base file to the equivalent path, but using the .js extension instead
sed -i -e "s|%layoutServiceHost%|$SITECORE_API_HOST|g" -e "s|309ec3e9-b911-4a0b-aa8d-425045b6dcbd|$SITECORE_API_KEY|g" $jsname - uses sed to perform a regex replace on the known values we baked into the base file, replacing them with the environment variables ($SITECORE_API_HOST and $SITECORE_API_KEY) that form the current runtime configuration for those values
Finally we need to get this script to run each time the container starts up. There are several ways we could do this, but I elected to add an npm script to the headless proxy’s package.json:
…and then changed the entry point in the Dockerfile to call the container entrypoint:
ENTRYPOINT npm run docker
The final step is to rebuild the container image so we can start it up, using docker build.
Using the tokenized container
The headless proxy Node app has always known how to read environment variables for the Sitecore API host and API key, but those have only applied to the SSR execution not the browser-side execution. With the modifications we’ve made, setting those same environment variables will now also apply to the browser. Doing this with Docker is quite trivial when booting the container, for example:
1
docker run -p 3000:3000 --env SITECORE_API_KEY=[yourkey] --env SITECORE_API_HOST=http://your.site.core [container-image-name]
Putting it together
For more clarity, here’s the full contents of the Dockerfile with all these changes made:
FROM node:lts as build RUN npm install -g @sitecore-jss/sitecore-jss-cli WORKDIR /build COPY jss-angular /build RUN npm install # setup to use static values we'll later replace with env vars # (for values that are baked into the server bundle) RUN jss setup --layoutServiceHost %layoutServiceHost% --apiKey 309ec3e9-b911-4a0b-aa8d-425045b6dcbd --nonInteractive RUN npm run build # Rename all .js files to .js.base (so we can bootstrap tokens later) RUN find dist/ -name '*.js' | xargs -I % mv % %.base
In this episode, we have improved the JSS headless container build process by running all of the build inside containers for improved repeatability and tokenized the browser JS bundles so that the same container can be deployed to many environments with different API hosts without needing a rebuild. What’s next? Orchestrating multiple instances with Kubernetes.
I’ve been playing with containers lately and as an experiment, containerized JSS Headless Mode. Since I had fun doing this, I figured I’d share what I learned. Note that this is my own explorations, and should not be construed as any official statement of container support for JSS, nor is it supported via official Sitecore channels.
Containers 101: What’s a container?
The best way to understand containers quickly is, of course, a meme.
Another way to think of a container is a lightweight virtual machine. Unlike a VM, a container shares much of its system with the host OS or node. This means that containers:
Are much smaller both in disk and memory usage compared to a VM
Do not provide as strong of an isolation from the host as a VM
Are more easily based on a standard distribution. For example in this post we won’t be building a container from scratch; we will take the standard node container and deploy JSS to it - thus, we offload the maintenance of the base container to the Node maintainers, and we take on the maintenance of only our app.
Containers have become incredibly popular as a way to build and deploy applications because of their consistency and low resource usage. Especially as more applications take on more server-based dependencies (i.e. microservice architectures, or even a traditional app that may need a database, search service, etc), containers provide a reasonable way to replicate such a complex IT infrastructure on a developer machine in the same way that it runs in production - without each developer needing to have a 1TB RAM, 28-core server to run all those virtual machines.
So with that in mind, what if we wanted to containerize Sitecore JSS’ headless mode host?
Note: we’re only containerizing the JSS SSR host in this post; the rest of the Sitecore infrastrucure would still need to be deployed traditionally.
Creating a JSS Docker container
If you’re planning to follow along at home with this build, note that you’ll need to install Docker Desktop in order to be able to locally build and run the containers. You may also need to enable virtualization in your UEFI, if it’s off, or potentially for Windows also enable Hyper-V and Containers features at an OS level. Consult the Docker docs for help with that :)
When you create a container, there are three main tasks:
Determine the base container to build from
Containers are built on top of other containers in an efficient and lightweight way. This means that for example, your container might start with a Windows Server container, or an Ubuntu container…or it might start from a Node container, that was based on an Debian container. You get the idea - containers, like ogres or ‘90s software architecture, have layers. Each layer is built as a diff from the underlying layer. When you make a container, you’re adding a layer.
In our case, JSS headless SSR is a Node-based application, so we will choose the Node container as our base.
Define the Dockerfile
The dockerfile is a file named Dockerfile that defines how to create your container. It defines things like:
What your base container is (FROM node:lts)
How to modify the base container to turn it into your container (scripts and file copying)
Defaults, like which TCP/UDP ports the container can expose
Then we want to tell Docker how to deploy our JSS app on top of the Node container. We do this by telling it which files we want to copy into the container image and where to put them, as well as any commands that need to be run to complete the setup:
# We want to place our app at /jss on the container filesystem
# (this is a fairly arbitrary choice;
# use something app-specific and don't use '/')
# Subsequent commands and copies are relative to this directory.
WORKDIR /jss
# Specify the _local_ files to copy into the container;
# in this case a copy of the headless SSR proxy: https://github.com/Sitecore/jss/tree/dev/samples/node-headless-ssr-proxy
COPY ./node-headless-ssr-proxy /jss
# Run shell commands _inside the container_ to set up the app;
# in this case, to install npm packages for the headless Node app.
# NOTE: the container is built on the Docker server, not locally!
# Commands you run here run inside the container, and thus
# cannot for example reference local file paths!
RUN npm install
# To run JSS in headless mode, we also need to deploy
# the JSS app's server build artifacts into the container
# for the headless mode proxy to execute. This is another copy.
COPY my-jss-app-name/dist /jss/dist/my-jss-app-name
# When the container starts, we have to make it do something
# aside from start - in this case, start the JSS app.
# The command is run in the context of the WORKDIR we set earlier.
ENTRYPOINT npm run start
# The JSS headless proxy is configured using environment variables,
# which allow us to configure it at runtime. In this case,
# we need to configure the port, app bundle, etc
ENV SITECORE_APP_NAME=my-jss-app-name
# Relative to /jss path to the server bundle built by the JSS app build
# Note: this path should be identical to the path deployed for integrated
# mode, so that path references work correctly.
ENV SITECORE_JSS_SERVER_BUNDLE=./dist/${SITECORE_APP_NAME}/server.bundle.js
# Hostname of the Sitecore instance to retrieve layout data from.
# host.docker.internal == DNS name of the docker host machine,
# i.e. to hit non-container localhost Sitecore dev instance
ENV SITECORE_API_HOST=http://host.docker.internal
ENV SITECORE_API_KEY=GUID-VALUE-HERE
# Enable or disable debug console output (dont use in prod)
ENV SITECORE_ENABLE_DEBUG=false
# Set the _local_ port to run JSS on, within the container
# (this does not expose it publicly)
ENV PORT=3000
# Tell Docker that we expose a port, but this is for documentation;
# the port must be mapped when we start the container to be exposed.
EXPOSE ${PORT}
Build the container
Once we have defined the steps necessary to create the container image, we need to build the container. Building the container:
Collects all the files in the Dockerfile directory and uploads them to the Docker host (unless listed in a .dockerignore file)
Acquires the base image, if it’s not already on the Docker host
Creates a container based on the base image and starts it
Executes your Dockerfile script within the container to configure it
Captures your Docker image and stores it for reuse
The Dockerfile does not execute locally, so make sure you don’t make that assumption when using EXEC directives; execution also occurs within the container being built, so it occurs in the context of the container (in this case, Debian) and the dependencies that are part of the container.
To build your JSS container, within the same folder as your Dockerfile run:
docker build -t your-image-name .
Once the build is done, you can find your image on Docker using:
docker images
Using the JSS Docker container
Up to this point we have collected and built the container, but nothing has been run. To create a new instance of your container and start it up, run
docker run -p 3000:3000 --name <pick-a-name-for-container-instance> <imagename>
The -p maps your localhost port 3000 to the container port 3000 (which we specified the Node host to run on previously using an environment variable).
Once you start the container, visiting http://localhost:3000 should run the app in the JSS headless host container.
Container Debugging Tips
Viewing running containers - list running containers using the docker ps command. If a container was started without an explicit --name, this can help find it.
Opening a shell in a container - to run diagnostic shell commands, you can open a root shell to a running container. The docker exec command lets you run commands, including starting a shell - for example, docker exec -it <container-name> bash. The -it says you want an interactive TTY (in other words an ongoing shell, not a one-off command execution and exit)
What’s Next?
In this post, we’ve created and run a Docker container of the JSS headless mode. This works great for a single container, but for production scenarios we would likely need to orchestrate multiple instances of the container to handle heavy load and provide redundancy. Next time, we will improve our container build script using a build container, then finally the series will end with orchestrating the container using Kubernetes.
I spent the first part of this week out at Build 2019, and I learned a lot! Here’s all the news I saw fit to print from Build in a concise, notesy format.
.NET Core 3
The next version of .NET Core will be released in September 2019. It will feature a raft of improvements, notably WPF/desktop app support (Windows only), .NET Standard 2.1 (not going to be supported by .NET 4.x ever), and C# 8 (.NET Standard 2.1 required).
Coinciding with the release of .NET Core 3 will be dotnetconf from September 23-25, a virtual conference highlighting .NET Core 3.
.NET Core 3.1, the long term support version, is slated to ship in November.
.NET 5 and the Unified BCL
After .NET Core 3 ships, .NET Core is dead. Instead .NET 5 will ship, and it will unify the abstraction of .NET Standard into a universal BCL that can run on any .NET 5 compatible runtime (i.e. Xamarin, Mono, Windows .NET). It will also gain Java and Swift interop capabilities (from Mono/Xamarin) on all platforms. The idea is that .NET 5 will be a singular platform that runs anywhere from mobile devices, to IoT/Raspberry Pi, to desktop apps, to cloud server(less).
Web Forms and WCF will never be ported to .NET Core/.NET 5. Specifically for Web Forms, Blazor will be the recommended migration path.
Following .NET 5, the .NET platform will have yearly releases (.NET 6, 7, 8, …). Alternating years will be LTS versions, in other words 2020’s .NET 5 will be supplanted by the LTS .NET 6 in 2021.
Note: C# 8 requires compiler changes that need .NET Standard 2.1+. In other words, C# 8 can only be used with .NET Core 3 and later as a consumer!
The main focus of C# 8 is “robustness.” There are a number of new features that support this goal:
Async Enumerable
Ever since async/await was shipped in C#, it’s been problematic to use it with enumerables because you must await either Task<IEnumerable<T>> (thus awaiting the WHOLE enumerable, which loses its lazy enumeration advantages), or IEnumerable<Task<T>> which potentially requires awaiting in a loop, which is also suboptimal. It also prevents the use of yield return in async methods, which makes them significantly less pretty.
In C# 8, this is fixed by introducing IAsyncEnumerable<T>, an asynchronously enumerable enumerable type. This type is enumerated using await foreach, i.e. await foreach(var t in asyncEnumerable) { /* where t is not a task */ }. The implementation of IAsyncEnumerable is simply allowed to yield return values, giving the enumerator control over its own internal asynchrony needs, batching, etc.
Nullable Reference Types
The NullReferenceException is everyone’s favorite C# bugbear, and solutions good and bad abound for asserting that method arguments are not null to avoid throwing them (my favorite is var x = arg ?? throw new ArgumentNullException(nameof(arg));). In C# 8, you can explicitly declare reference types as nullable, explicitly stating that a method can return - or accept - a null value. Doing this allows the compiler to remove the need for all those assertions, as it can warn you at compile time if you’re not checking a nullable type for null before using it. This is an opt-in feature either with #nullable enable in a file, or it can be turned on per-project.
1 2 3 4 5 6 7 8 9 10 11 12
Item? GetItem() { // ... }
void DoStuff() { // with nullable reference types on, this will throw a compiler warning // because GetItem declared explicitly that it can return null var troll = GetItem().Axes.GetDescendants();
// you can bypass the warning if you know what you're doing (lol) with ! var explodingTroll = GetItem()!.Axes.GetDescendants(); }
Range Expressions
A common need is to parse a string or array and split it up into pieces by index; for example “this string’s last two characters” or “the first 5 elements in this array.” This sort of code is quite vulnerable to naughty data input causing exceptions, for example "a".Substring(5) will throw because it isn’t 5 characters long.
C# 8 range expressions allow you to concisely and safely (they won’t throw if the array is shorter than the slice) express this sort of problem. They work using ^ to anchor the range to “length - x” or “start + x”, a spread, and an optional endpoint. A few examples:
1 2 3 4
var str = "hello world"; var a = str[0..5]; // 'hello' var b = str[^1]; // 'd' var c = str[^1..^4]; // 'ello w'
Switch Expressions
The switch statement receives an upgrade in C# 8 with the ability to assign it directly to a variable, eliminating the need for clumsy break statements in every case. It’s also possible to use pattern matching with this format (not pictured).
1 2 3 4 5 6
var result = "hello" switch { "hello" => true, "goodbye" => false, _ => false // default case via a discard }; // result = true
Default Interface Implementations
Interfaces can have default implementations for members. This is not intended to kill IoC containers as much as be a tool for API creators to ship additions to public interfaces without breaking existing consumers of that interface. The additional members need only be optionally implemented by downstream consumers, with the defaults used if not overridden.
Using Declarations
The using statement gets an overhaul to avoid needing a block scope. A using statement is used to prevent forgetting to dispose IDisposable resources, but before C# 8 it required a block scope of its own which especially in nested usings made things hard to read. In C# 8, you can define a variable with the using keyword and no block scope, and it is implicitly disposed at the end of the current block scope. For example:
1 2 3 4
public void Foo() { using var file = new FileStream(@"c:\foo.txt"); // file will be disposed when the Foo() block exits }
In TypeScript 3.4 - currently RC - you can enable incremental builds (via tsconfig, or --incremental to the CLI), which allows TS to cache the output of the last build/watch run and essentially ‘rehydrate’ it during the next build to avoid rebuilding unchanged modules. The upshot of this on the VS Code codebase is that warm build times went from 47 seconds to 11 seconds.
On larger TypeScript codebases, using project references can allow TypeScript to partition compilation units, enabling it to only rebuild changed units in the dependency tree (about like projects and solutions in Visual Studio). This can be used to avoid needing to recompile an entire TypeScript project every time even without incremental builds.
New modernized TypeScript documentation, with content oriented around current TypeScript practices and improved clarity, is in process. Current target is late 2019 to release the new docs.
Using Live Share developers can collaborate effectively while remote, with either Visual Studio, VS Code, or both. It’s a bit like a code-specific combination of screen sharing and collaborative editing. This includes things like:
Editing code in a Google Docs-like collaborative realtime editor
Setting breakpoints, controlling debugger execution that executes on the host’s computer
Reviewing the other dev’s localhost ports
VS Code can live share with Visual Studio
The viewer need not have a SDK, debugger, or plugins for the host’s code to participate - or even the same CPU architecture.
Works across platforms too, so you could connect using Code on a Mac to VS on Windows and control debugging a windows service, for example.
Code can now connect to a remote system (via SSH or directly to a container) and edit the remote instance as if it were local files. This includes things like installing Code plugins on the remote environment - it’s basically connecting to a “headless” VS Code service. For example, you could write Ruby code on a Docker container in AKS from a windows machine running Code…without needing to set up a Ruby dev environment locally or install any Ruby plugins into Code. Or, do .NET Core dev on a remote VM without needing to install the .NET Core SDK locally.
Remote editing really shines when combined with Azure Dev Spaces (read on…).
There were excellent sessions on getting more out of Visual Studio and VS Code. If you want to learn something about your tools, these were pretty great. For example:
You can configure Code to attach multiple debuggers at launch (i.e. Chrome + Node debuggers)
F1 opens the Code palette, in addition to Ctrl-P
You can quickly open files in Code from the command palette by removing the > prompt and typing a filename or expression
Jump to outlined functions, tags, etc the current file, in Code, by entering @: in the command palette (i.e. @:myfunc)
IntelliCode (available in Code and VS 16.1+) applies ML models to predict the most commonly used code completions for a given state. For example if(arrayVar. might suggest Length but stringVar. might suggest Split. The suggestions model was trained on 2000 of the most popular open source codebases on GitHub, so they’re based on actual community practices.
Visual Studio is aggressively rendering R# irrelevant in current previews. You really might not need it at all in the future. Tons of new refactorings, code cleanup improvements, ability to infer .editorconfig files, et al.
It’s no secret that microservice architectures can be pretty difficult to develop locally. Especially if they tend towards the distributed monolith antipattern ;) Well, Azure decided to do something about that. Probably the coolest demo of the whole event.
Dev Spaces is a prebuilt microservice-oriented workflow for developers based on Azure Kubernetes Service (AKS). The basic concept is that a dev team would share an AKS cluster across their whole team - because developers would probably be working on a few microservices, not the whole galaxy of the system, they can then basically “branch” specific microservices out for personal development, while referencing the rest of the system built from the latest CI build. In other words, there’s no need to mock or setup local microservices that you don’t care about, because yours runs in AKS and refers to the master build.
Even more bonkers, you can use remote development to debug and auto-deploy files to your personal microservices running in AKS. Pull requests can be made to similarly build in their own namespace, giving faster and more efficient use of build time. Seems like a pretty darn nice experience, with most of the orchestration issues no longer your problem.
You can define your Azure DevOps build and release pipelines using YAML files that can be committed to the repository. This allows the build system to be versioned and stable across branches and enables proper testing of changes to the build via PRs. In preview now, release pipelines (in addition to builds) can be defined in YAML. There is also a visual editor that allows generation of YAML for common tasks using a GUI.
Coming soon, pipelines will be able to automatically generate a Kubernetes manifest and Helm chart for any project with a Dockerfile. This will also generate appropriate build YAML to allow building docker images, deploying them to Azure Container Registry, and spinning up the Kubernetes cluster from those images on Azure Kubernetes Service. Looks really easy to use, and a definite lowering of the barrier to entry to Kubernetes deployment. The pipeline doesn’t only support Azure k8s either; it can deploy to other container registries or k8s clusters on premise or in other clouds.
Azure Cognitive Search
Azure search is gaining the ability to apply cognitive services to data being indexed; for example it can index the contents of images as detected by cognitive services, etc. Also the 1000-field limit that Sitecore users love is being investigated and may be raised or eliminated in a near term time frame.
ML.NET 1.0 & AutoML
A library to build and run machine learning models from within .NET. Can consume several trained model formats, including TensorFlow, which lets you integrate ML models built by a data scientist using Python et al into .NET runtimes. Microsoft is also working on the ONNX model format for interoperable models. While it’s capable of training its own models too, it is interesting to see the model promoted where data scientists do their modeling using mainstream ML tools (i.e. Python), and deploy only the trained model to the .NET application. Promising in terms of integrating .NET with mainstream data scientists.
The AutoML toolkit was also announced. AutoML is a nice looking tool for non-data-scientists to take a dataset and automatically discover a good ML algorithm and hyperparameter set to produce an accurate model. Definitely aimed at the backend developer looking to add a splash of ML to their toolset, as opposed to data scientists, but this seems like it could significantly lower the barrier to ML entry for .NET developers.
When building a single-page app with Sitecore JSS and defining internal links in Sitecore content, you may notice that clicking the link in the JSS app does not act like a single page app. Instead the link click causes a full page refresh to occur, because the routing library used by the app is not aware that the link emitted by JSS can be treated as a route link.
Maybe you don’t want that to happen, because you like the fluidity of single-page apps or want to reduce bandwidth. Excellent! You’ve come to the right place.
The following examples use React, but the same architectural principles will translate well to Vue or Angular apps and the JSS field data schema is identical.
There are two places where we can receive links back from Sitecore:
Link Fields
Sitecore supports content fields that are explicitly hyperlinks (usually General Link fields, also referred to as CommonFieldTypes.GeneralLink in JSS disconnected data). When returned these fields contain link data (a href, optionally body text, CSS class, target, etc). In JSS apps, these are rendered using the Link component like so:
1 2 3 4
import { Link } from'@sitecore-jss/sitecore-jss-react';
To make JSS general links render using react-router links for internal links, we can create a component that conditionally chooses the link component like this:
import React from'react'; import { Link } from'@sitecore-jss/sitecore-jss-react'; // note we're aliasing the router's link component name, since it conflicts with JSS' link component import { Link as RouterLink } from'react-router-dom';
/** React component that turns Sitecore link values that start with / into react-router route links */ const RoutableSitecoreLink = (props) => { const hasValidHref = props.field && props.field.value && props.field.value.href; const isEditing = props.editable && props.field.editable;
// only want to apply the routing link if not editing (if editing, need to render editable link value) if(hasValidHref && !isEditing) { const value = props.field.value;
// determine if a link is a route or not. This logic may not be appropriate for all usages. if(value.href.startsWith('/')) { return ( <RouterLinkto={value.href}title={value.title}target={value.target}className={value.class}> {props.children || value.text || value.href} </RouterLink> ); } }
return<Link {...props} />; };
// usage - drop-in replacement for JSS' Link component exportdefault MyJSSComponent = (props) => <RoutableSitecoreLinkfield={props.fields.externalLink} />;
With this component, now your internal link values will be turned into router links and result in only a new fetch of route data instead of a page refresh!
Rich Text Fields
Rich Text fields are a more interesting proposition because they contain free text that is placed into the DOM, and we cannot inject RouterLink components directly into the HTML blob. Instead we can use React’s DOM access to attach an event handler to the rich text markup after it’s rendered by React that will trigger route navigation.
Similar to the general link field handling, we can wrap the JSS default RichText component with our own component that selects whether to bind the route handling events based on whether we’re editing the page or not:
/** Binds route handling to internal links within a rich text field */ classRouteLinkedRichTextextendsReact.Component{ constructor(props) { super(props);
// handler function called on click of route links // pushes the click into the router history thus changing the route // props.history comes from the react-router withRouter() higher order component. routeHandler(event) { event.preventDefault(); this.props.history.push(event.target.pathname); }
// rebinds event handlers to route links within this component // fired both on mount and update bindRouteLinks() { const hasText = this.props.field && this.props.field.value; const isEditing = this.props.editable && this.props.field.editable;
if(hasText && !isEditing) { const node = ReactDOM.findDOMNode(this); // selects all links that start with '/' - this logic may be inappropriate for some advanced uses const internalLinks = node.querySelectorAll('a[href^="/"]');
internalLinks.forEach((link) => { // the component can be updated multiple times during its lifespan, // and we don't want to bind the same event handler several times so unbind first link.removeEventListener('click', this.routeHandler, false); link.addEventListener('click', this.routeHandler, false); }); } }
// called once when component is created componentDidMount() { this.bindRouteLinks(); }
// called if component data changes _after_ created componentDidUpdate() { this.bindRouteLinks(); }
render() { // strip the 'staticContext' prop from withRouter() // to avoid confusing React before we pass it down const { staticContext, ...props } = this.props;
return<RichText {...props} />; } };
// augment the component with the react-router context using withRouter() // this gives us props.history to push new routes RouteLinkedRichText = withRouter(RouteLinkedRichText);
Now internal links entered in rich text fields will also be treated as route links.
Advanced Usages
These examples use simple internal link detection that consists of “starts with /.” There are some edge cases that can defeat simple link detection, such as:
Scheme-insensitive links (//google.com) that are HTTP or HTTPS depending on the current page. These are an antipattern; encrypt all your resources.
Links to static files (i.e. media files).
For use cases such as this, more advanced detection of internal links may be required that is situational for your implementation.
Page weight - how much data a user needs to download to view your website - is a big deal in JavaScript applications. The more script that an application loads, the longer it takes to render for a user - especially in critical mobile scenarios. The longer it takes an app to render, the less happy the users of that app are. JavaScript is especially important to keep lightweight, because JS is not merely downloaded like an image - it also has to be parsed and compiled by the browser. Especially on slower mobile devices, this parsing can take longer than the download! So less script is a very good thing.
Imagine a large Sitecore JSS application, with a large number of JavaScript components. With the default JSS applications the entire app JS must be deployed to the user when any page in the application loads. This is simple to reason about and performs well with smaller sites, but on a large site it is detrimental to performance if the home page must load 40 components that are not used on that route in order to render.
Enter Code Splitting
Code Splitting is a term for breaking up your app’s JS into several chunks, usually via webpack. There are many ways that code splitting can be set up, but we’ll focus on two popular automatic techniques: route-level code splitting, and component-level code splitting.
Route-level code splitting creates a JS bundle for each route in an application. Because of this, it relies on the app using static routing - in other words knowing all routes in advance, and having static components on those routes. This is probably the most widespread code splitting technique, but it is fundamentally incompatible with JSS because the app’s structure and layout is defined by Sitecore. We do not know all of the routes that an app has at build time, nor do we know which components are on those routes because that is also defined by Sitecore.
Component-level code splitting creates a JS bundle for each component in an application. This results in quite granular bundles, but overall excellent compatibility with JSS because it works great with dynamic routing - we only need to load the JS for the components that an author has added to a given route, and they’re individually cacheable by the browser providing great caching across routes too.
Component-level Code Splitting with React
The react-loadable library provides excellent component-level code splitting capabilities to React apps. Let’s add it to the JSS React app and split up our components!
Step 1: Add react-loadable
We need some extra npm packages to make this work.
// npm npm i react-loadable npm i babel-plugin-syntax-dynamic-import babel-plugin-dynamic-import-node --save-dev
Step 2: Make the componentFactory use code splitting
In order to use code splitting, we have to tell create-react-app (which uses webpack) how to split our output JS. This is pretty easy using dynamic import, which works like a normal import or require but loads the module lazily at runtime. react-loadable provides a simple syntax to wrap any React component in a lazy-loading shell.
In JSS applications, the Component Factory is a mapping of the names of components into the implementation of those components - for example to allow the JSS app to resolve the component named 'ContentBlock', provided by the Sitecore Layout Service, to a React component defined in ContentBlock.js. The Component Factory is a perfect place to put component-level code splitting.
In a JSS React app, the Component Factory is generated code by default - inferring the components to register based on filesystem conventions. The /scripts/generate-component-factory.js file defines how the code is generated. The generated code - created when a build starts - is emitted to /src/temp/componentFactory.js. Before we alter the code generator to generate split components, let’s compare registering a component in each way:
// loadable dynamic import component - lazily loads the component implementation when it is first used const ContentBlock = Loadable({ // setting webpackChunkName lets us have a nice chunk filename like ContentBlock.hash.js instead of 1.hash.js loader: () =>import(/* webpackChunkName: "ContentBlock" */'../components/ContentBlock'), // this is a react component shown while lazy loading. See the react-loadable docs for guidance on making a good one. loading: () =><div>Loading...</div>, // this module name should match the webpackChunkName that was set. This is used to determine dependency during server-side rendering. modules: ['ContentBlock'], });
// after const imports = []; imports.push(`import React from 'react';`); imports.push(`import Loadable from 'react-loadable';`);
// change imports.push(``import ${importVarName} from '../components/${componentFolder}';``); to imports.push(LoadableComponent(importVarName, componentFolder));
You can find a completed gist of these changes here. Search in it for [CS] to see each change in context. Don’t copy the whole file, in case of future changes to the rest of the loader.
Try it!
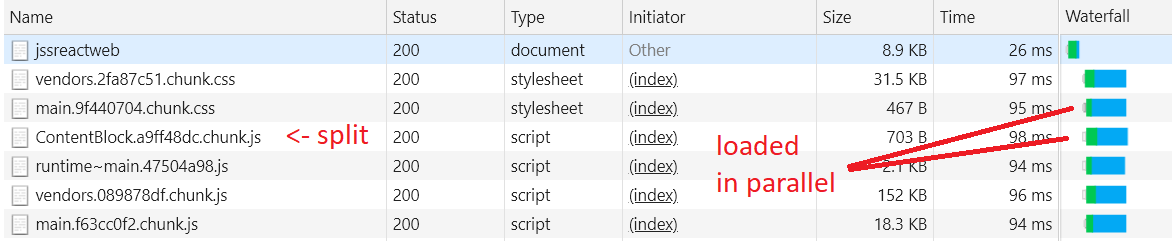
Start your app up with jss start. At this point Code Splitting should be working: you should see a JS file get loaded for each component on a route, and a short flash of Loading... when the route initially loads.
But it still has some issues that could make it more usable. If the app is server-side rendered in headless or integrated modes none of the content will be present because the dynamic imports are asynchronous and have not resolved before the SSR completes. We’d also love to avoid that flash of loading text if the page was server-side rendered, too. Well guess what, we can do all of that!
Step 3: Configure code splitting for Server-Side Rendering
Server-side rendering with code splitting is a bit more complex. There are several pieces that the app needs to support:
Preload all lazy loaded components, so that they render immediately during server-side rendering instead of starting to load async and leaving a loading message in the SSR HTML.
Determine which lazy loaded components were used during rendering, so that we can preload the same components’ JS files on the client-side to avoid the flash of loading text.
Emit <script> tags to preload the used components’ JS files on the client side into the SSR HTML.
3.1: Configure SSR Webpack to understand dynamic import
The build of the server-side JS bundle is separate from the client bundle. We need to teach the server-side build how to compile the dynamic import expressions. Open /server/server.webpack.config.js.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
// add these after other imports const dynamicImport = require('babel-plugin-syntax-dynamic-import'); const dynamicImportNode = require('babel-plugin-dynamic-import-node'); const loadableBabel = require('react-loadable/babel');
// add the plugins to your babel-loader section //... use: { loader: 'babel-loader', options: { babelrc: false, presets: [env, stage0, reactApp], // [CS] ADDED FOR CODE SPLITTING plugins: [dynamicImport, dynamicImportNode, loadableBabel], },
You can find a completed gist of these changes here. Search in it for [CS] to see each change in context. Don’t copy the whole file, in case of future changes to the rest of the webpack config.
3.2: Configure server.js
The /server/server.js is the entry point to the JSS React app when it’s rendered on the server-side. We need to teach this entry point how to successfully execute SSR with lazy loaded components, and to emit preload script tags for used components.
// add after const graphQLClient... const loadableModules = [];
// add after initializei18n()... .then(() => Loadable.preloadAll())
// wrap the `<AppRoot>` component with the loadable used-component-capture component <Loadable.Capture report={(module) => loadableModules.push(module)}> <AppRootpath={path}Router={StaticRouter}graphQLClient={graphQLClient} /> </Loadable.Capture>
// append another .replace() to the rendered HTML transformations .replace('<script>', `${convertLoadableModulesToScripts(loadableModules)}<script>`);
You can find a completed gist of these changes herewith better explanatory comments. Search in it for [CS] to see each change in context. Don’t copy the whole file, in case of future changes to the rest of the entry point.
3.3: Configure client-side index.js
The /src/index.js is the entry point to the JSS React app when it’s rendered on the browser-side. We need to teach this entry point how to wait to ensure that all preloaded components that SSR may have emitted to the page are done loading before we render the JSS app the first time to avoid a flash of loading text.
1 2 3 4 5
// add to the top import Loadable from'react-loadable';
// add after i18ninit() .then(() => Loadable.preloadReady())
You can find a completed gist of these changes here. Search in it for [CS] to see each change in context. Don’t copy the whole file, in case of future changes to the rest of the entry point.
Step 4: Try it out
With the code changes to enable splitting complete, deploy your app to Sitecore and try it in integrated mode. You should see the SSR HTML include a script tag for every component used on the route, and the rendering will wait until the components have preloaded before showing the application. This preloading means the browser does not have to wait for React to boot up before beginning load of the components, resulting in a much faster page load time.
The ideal component loading technique for each app will be different depending on the number and size of each component. Using the standard JSS styleguide sample app, enabling component code-splitting like this resulted in transferring almost 40k less data when loading the home page (which has a single component) vs the styleguide page (which has many components). This difference increases with the total number of components in a JSS app - but for most apps, code splitting is a smart idea if the app has many components that are used on only a few pages.
It’s possible to deploy server-side rendered Sitecore JSS sites in disconnected mode. When deployed this way, the JSS app will run using disconnected layout and content data, and will not use a Sitecore backend.
Why would I want this?
In a word, previewing. Imagine during early development and prototyping of a JSS implementation. There’s a team of designers, UX architects, and frontend developers who are designing the app and its interactions. In most cases, Sitecore developers may not be involved yet - or if they are involved, there is no Sitecore instance set up.
This is one of the major advantages of JSS - using disconnected mode, a team like this can develop non-throwaway frontend for the final JSS app. But stakeholders will want to review the in-progress JSS app somewhere other than http://localhost:3001, so how do we put a JSS site somewhere shared without having a Sitecore backend?
Wondering about real-world usage? The JSS docs use this technique.
How does it work?
Running a disconnected JSS app is a lot like headless mode: a reverse proxy is set up that proxies incoming requests to Layout Service, then transforms the result of the LS call into HTML using JS server-side rendering and returns it. In the case of disconnected deployment instead of the proxy sending requests to the Sitecore hosted Layout Service, the requests are proxied to the disconnected layout service.
Setting up a disconnected app step by step
To deploy a disconnected app you’ll need a Node-compatible host. This is easiest with something like Heroku or another PaaS Node host, but it can also be done on any machine that can run Node. For our example, we’ll use Heroku.
Ensure the app has no scjssconfig.json in the root. This will make the build use the local layout service.
Create a build of the JSS app with jss build. This will build the artifacts that the app needs to run.
Install npm packages necessary to host a disconnected server: yarn add @sitecore-jss/sitecore-jss-proxy express (substitute npm i --save if you use npm instead of yarn)
Deploy the following code to /scripts/disconnected-ssr.js (or similar path). Note: this code is set up for React, and will require minor tweaks for Angular or Vue samples (build -> dist)
// the port the disconnected app will run on // Node hosts usually pass a port to run on using a CLI argument const port = process.argv[2] || 8080;
// create a JSS disconnected-mode server createDefaultDisconnectedServer({ port, appRoot: __dirname, appName, language, server, afterMiddlewareRegistered: (expressInstance) => { // to make disconnected SSR work, we need to add additional middleware (beyond mock layout service) to handle // local static build artifacts, and to handle SSR by loopback proxying to the disconnected // layout service on the same express server
// Serve static app assets from local /build folder into the sitecoreDistPath setting // Note: for Angular and Vue samples, change /build to /dist to match where they emit build artifacts expressInstance.use( sitecoreDistPath, express.static('build', { fallthrough: false, // force 404 for unknown assets under /dist }) );
const ssrProxyConfig = { // api host = self, because this server hosts the disconnected layout service apiHost: `http://localhost:${port}`, layoutServiceRoute: '/sitecore/api/layout/render/jss', apiKey: 'NA', pathRewriteExcludeRoutes: ['/dist', '/build', '/assets', '/sitecore/api', '/api'], debug: false, maxResponseSizeBytes: 10 * 1024 * 1024, proxyOptions: { headers: { 'Cache-Control': 'no-cache', }, }, };
// For any other requests, we render app routes server-side and return them expressInstance.use('*', scProxy(app.renderView, ssrProxyConfig, app.parseRouteUrl)); }, });
Test it out. From a console in the app root, run node ./scripts/disconnected-ssr.js. Then in a browser, open http://localhost:8080 to see it in action!
Deploying the disconnected app to Heroku
Heroku is a very easy to use PaaS Node host, but you can also deploy to Azure App Service or any other service that can host Node. To get started, sign up for a Heroku account and install and configure the Heroku CLI.
We need to tell Heroku to build our app when it’s deployed.
Locate the scripts section in the package.json
Add the following script:
1
"postinstall": "npm run build"`
We need to tell Heroku the command to use to start our app.
Create a file in the app root called Procfile
Place the following contents:
1
web: node ./scripts/disconnected-ssr.js $PORT
To deploy to Heroku, we’ll use Git. Heroku provides us a Git remote that we can push to that will deploy our app. To use Git, we need to make our app a Git repository:
1 2 3
git init git add -A git commit -m "Initial commit"
Create the Heroku app. This will create the app in Heroku and configure the Git remote to deploy to it. Using a console in your app root:
1
heroku create <your-heroku-app-name>
Configure Heroku to install node devDependencies (which we need to start the app in disconnected mode). Run the following command:
Sitecore Team X is proud to announce the final public release of Sitecore JavaScript Services (JSS) with full XSLT 3.0 support!
Why XSLT 3.0?
XSLT 3.0 allows for JSON transformations, so you can use the full power of modern JSS while retaining the XSLT developer experience that Site Core developers know and love.
Our XSLT 3.0 engine allows for client-side rendering by transforming hard-to-read JSON into plain, sensible XML using XSLT 3.0 standards-compliant JSON-to-XML transformations. Instead of ugly JSON, your JSS renderings can simple, easy to read XML like this:
JSON transformations allow XSLT 3.0 to be a transformative force on the modern web. Expect to see recruiters demand 10 years of XSLT 3.0 experience for Site-core candidates within the next year - this is a technology you will not want to miss out on learning.
Dynamic XSLT with VBScript
Modern JavaScript is way too difficult, so we’ve implemented a feature that lets you define dynamic XSLT templates using ultra-modern VBScript:
The Sitecore JSS team is always looking for opportunities to improve JSS and make it compatible with the most modern technologies. Experimentation is already under way to add ColdFusion scripting support for XSLT 3 JSS renderings, and enable PHP server-side rendering for your SiteCore solutions.
Just another way that we help you succeed in your Site core implementations.
Since Sitecore 9 was released, there’s been a lot of talk about the new installation techniques that it necessitates - namely, the move towards infrastructure as code and the Sitecore Install Framework (SIF). It’s no secret that installing Sitecore 9 can be a bit more difficult than previous versions, but it really doesn’t have to be.
This is the part where you might be expecting me to announce some crazy script I wrote, but not this time because someone else already did the work. So let’s address the elephant in the room.
Seriously, it’s awesome and you should use it especially for local dev setups.
A few things I noted when I used it:
Change the download URLs for Solr and NSSM to be https (encrypted). They work fine that way.
You must install the Java Runtime Environment (JRE) first and plug in the right version - it won’t do it for you
Make sure to add the $SolrHost value to your hosts file before you run the script so that it can resolve with the SSL certificate correctly (it will be bound to that name; don’t use localhost).
SIF the easy way with SIFless
SIF is a pretty amazing tool, but it has two shortcomings: one, that it’s great for automated infrastructure but not so great for a quick local setup and two, that it doesn’t yet have an uninstall feature. Well Rob Ahnemann wrote a handy GUI for SIF called SIFless that fixes both of those issues, making quick setups with mostly default settings easy and generating hackable SIF PowerShell scripts that let you do whatever advanced things you want after using the GUI to get started. And it generates uninstall scripts too that get rid of the windows services, solr cores, and other artifacts that are left when you want to tear down that test site.
A few things to be aware of with SIFless:
Despite the amusing name, SIFless does require SIF to be installed!
The Solr URL needs to be the path to the Solr admin panel (e.g. not https://mysolr:8983, but https://mysolr:8983/solr)
The Solr physical path needs to be to the root of the Solr instance (if it’s the right place you’ll see ‘bin’ and ‘server’ folders; if you used the script above with defaults this would be C:\solr\solr-6.6.2)
Go forth and use Sitecore 9
Using these two tools I went from having no Solr and no Sitecore installations to having a fully operational battle station Sitecore 9 instance with xConnect in about 45 minutes. And that includes debugging my own silly mistakes. I bet you can do it faster. Get thee to a PowerShell console!